
6.1 Introduction to Biological Databases

Figure 0.1: Logos from several biological databases
Learning Objectives
- Explain what a biological database is and why it’s important
- Name 3 types of information that may be available in biological databases.
6.1.1 What is a biological database?
The process of scientific discovery involves a great deal of collaboration. Different people do different experiments and find out different small pieces of the puzzle, and as we bring the information together we start to understand the big picture. This is true for expert scientists as well as beginners - we all need a way to find out what other people have already learned, and to share any new information we discover.
An important part of collaboration is sharing the data we collect with each other.
Recent technologies have allowed us to collect huge amounts of biological data. What kinds of data?
- Genomic DNA sequences of many organisms
- Gene activity across different organisms, tissues, and cell types
- Protein structures
- Enzymatic reactions and metabolic pathways
- Orthologs (genes that have similar sequences and functions across different organisms)
Biological databases are a way for scientists to organize and share their data. Most of this data is publicly available, if you know where to look. We’ll take a quick look at some important biological databases to give you an idea of what’s out there.
Many biological databases have websites for accessing the data. However, they are not always the most intuitive and user-friendly. It can be a bit overwhelming trying to explore these databases and understand the huge wealth of information they provide, even for experienced scientists. Don’t be afraid to ask for help!
We will now take a quick tour of some important biological databases and see the types of information they have available.
6.1.2 GenBank (Genomes)
The DNA sequence of the genomes for many important organisms can be found in the GenBank database. GenBank is maintained by the National Center for Biotechnology (NCBI).
Here is the entry for the human genome.
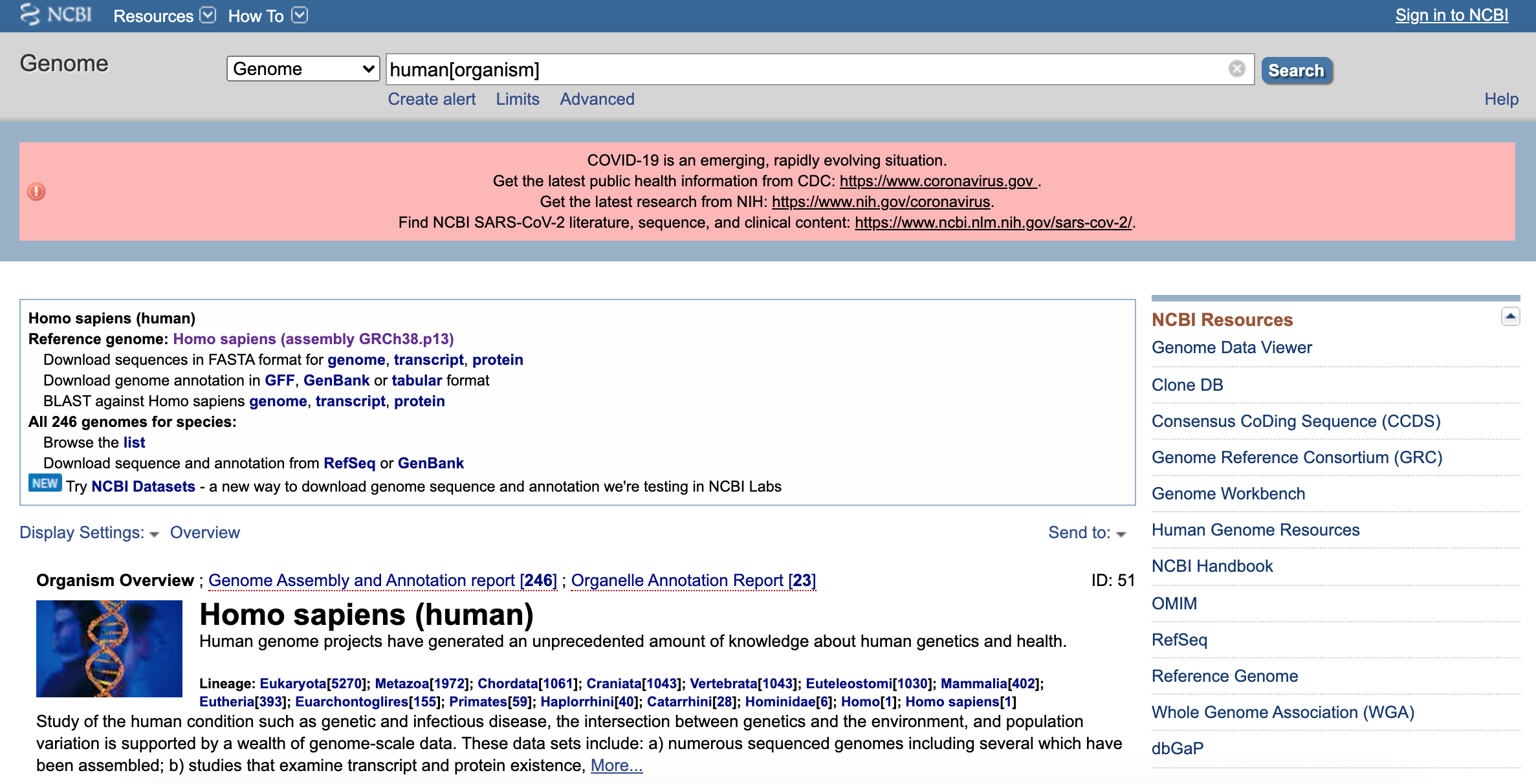
Figure 6.1: Katherine Cox (2020). Screenshot of Human Genome page from GenBank https://www.ncbi.nlm.nih.gov/genome/?term=human[organism]. License: CC BY 4.0
If you wanted, you could download it yourself! It wouldn’t make much sense to look at, it’s just a long series of A, T, C, and G. We need other computer programs and more research to help us make sense of the DNA sequence. But it is freely available for anyone to access.
GenBank has many other sequences - whole genomes, individual genes, and partial sequences from many different organisms.
This screenshot was taken in 2020. As you can see from the image, NCBI was being used to maintain a collection of resources for research on the novel coronavirus causing COVID-19.
6.1.3 OMIM (Genes)
As genes are discovered, the scientists who discover them get to name them and give them a gene symbol. Usually the gene name tells you something about what the gene does. This system works pretty well, but sometimes there are problems - two scientists might both discover the same gene and give it two different names, or there might be two genes with similar functions that are given the same name. In order to keep accurate track of all these genes, each gene is given a unique ID number.
There are a few databases (including GenBank) that act as central repositories for genes from all organisms. Then there are databases focused on individual organisms or specific categories of genes. One of the challenges of bioinformatics is keeping track of all the available information and matching up information from different databases.
One example of an organism-specific database is the Online Mendelian Inheritance in Man (OMIM) database. This database stores information about human genes and the diseases caused by mutations in these genes.
Here is the entry for CFTR, from OMIM. Mutations in CFTR lead to cystic fibrosis:
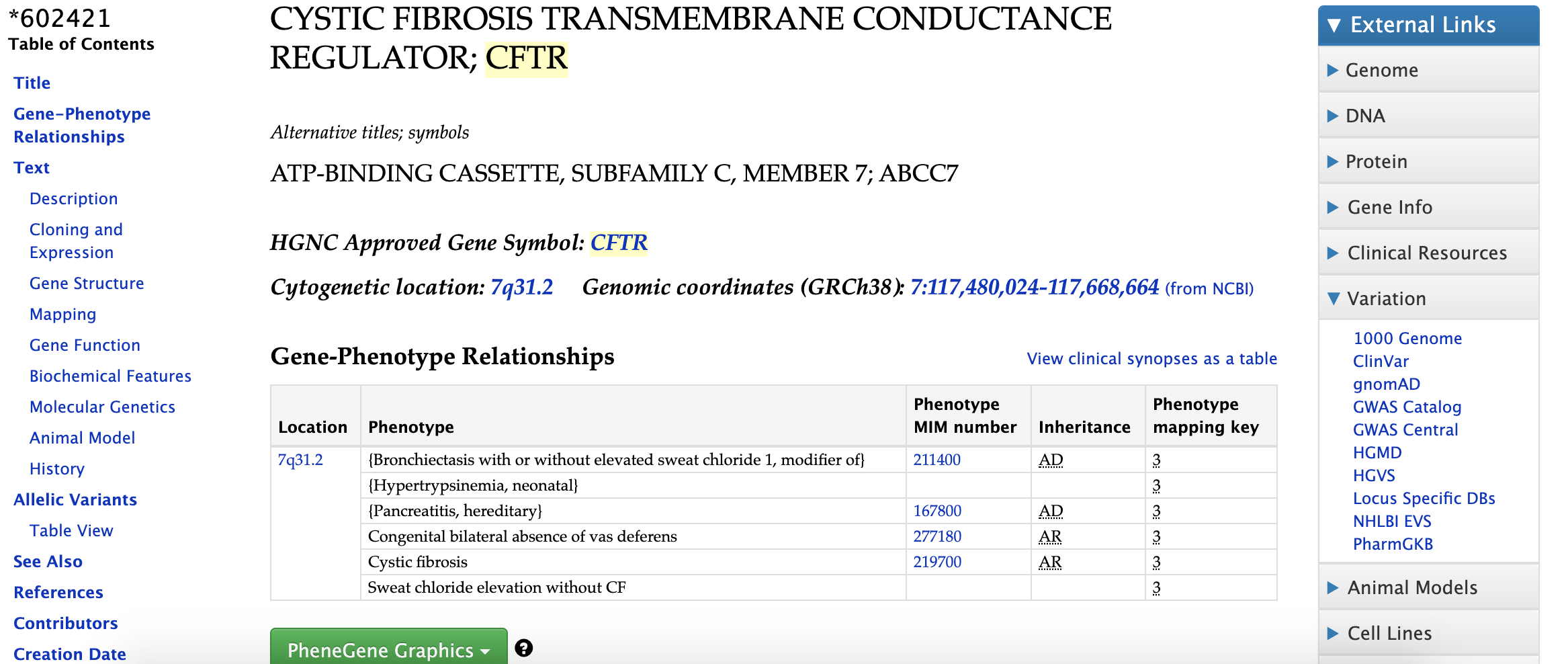
Figure 5.1: Katherine Cox (2021). Screenshot of the cystic fibrosis transmembrane conductance regulator page from Online Mendelian Inheritance in Man https://www.omim.org/entry/602421. License: CC BY 4.0
The top of the page lists the gene symbol and its location in the human genome, as well as phenotypes associated with the gene (how it affects the organism, including causing cystic fibrosis). If you scroll further down, it has much more information about what we know about the gene, what research has been done, and how studies are being carried out in other organisms to help us understand this gene.
6.1.4 Human Protein Atlas (Gene Activity)
Besides just knowing gene sequences and location in the genome, scientists are interested in gathering data about where and when those genes are active (“expressed”). Knowing when and where a gene is active can help us figure out what it does. The Human Protein Atlas is one database that collects gene expression data for human genes.
Here is the expression data for CFTR:
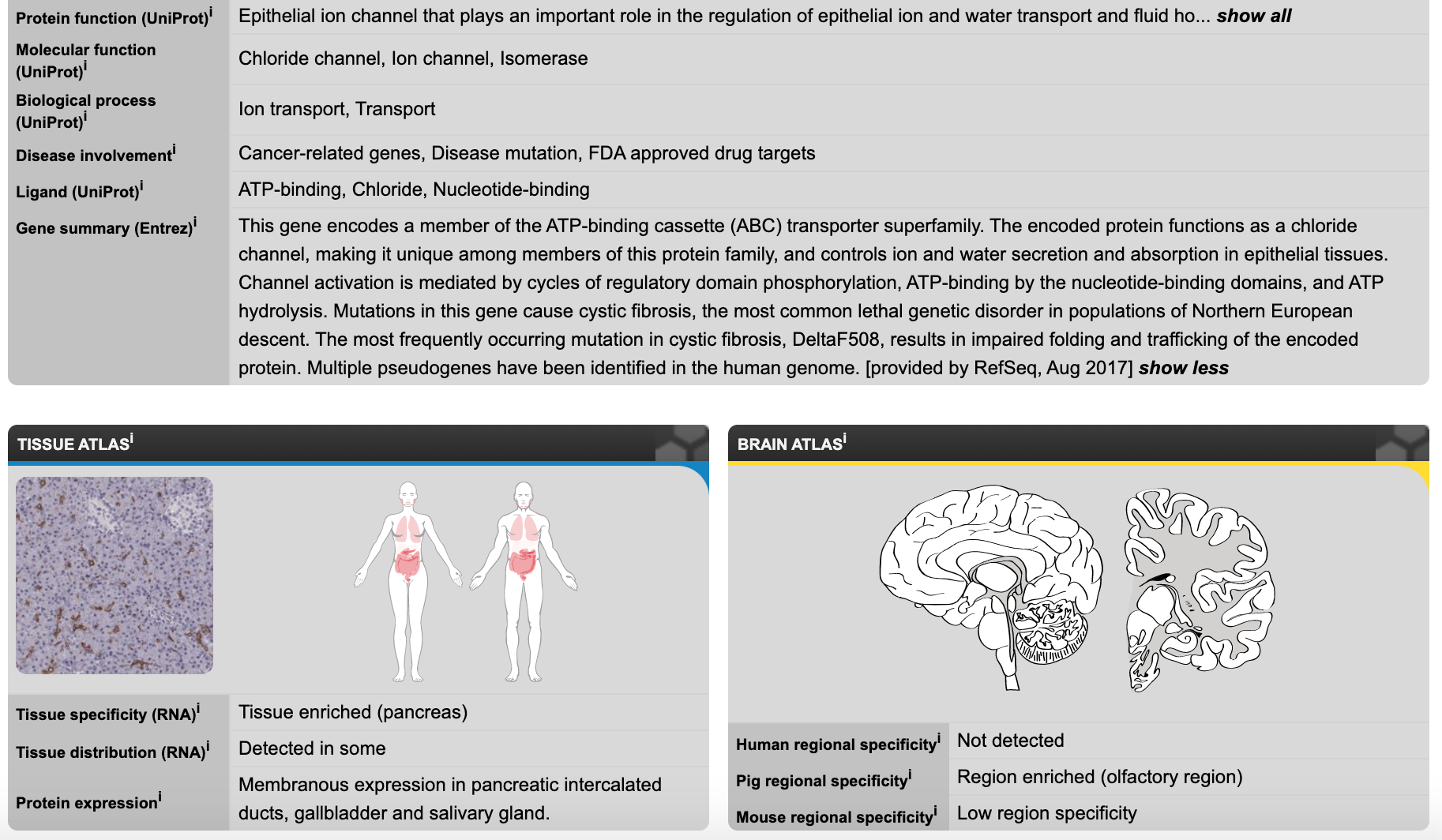
Figure 5.2: Katherine Cox (2021). Screenshot of the cystic fibrosis transmembrane conductance regulator page from Human Protein Atlas https://www.proteinatlas.org/ENSG00000001626-CFTR. License: CC BY 4.0
This screenshot is scrolled down a bit from the top of the page so you can see the expression data summary. As you can see, the CFTR gene is enriched in the pancreas, and is also expressed in a few other locations. It was not detected in the brain. If you click on either of these expression summaries you can get more detailed information. Further down on the page there is also information about subcellular localization (where in the cell is it located).
6.1.5 PDB (Protein Structures)
Studying the structure of proteins can tell us something about how they work, or about what goes wrong when they don’t work. For example, sickle cell anemia is caused by a single mutation in a gene for a subunit of hemoglobin. This mutation causes the hemoglobin to stick together, forming long fibers that deform red blood cells.
The Protein Data Bank (PDB) stores information about the structure of proteins. Here is the entry for Hemoglobin S (the sickle-cell form of hemoglobin) from PDB:
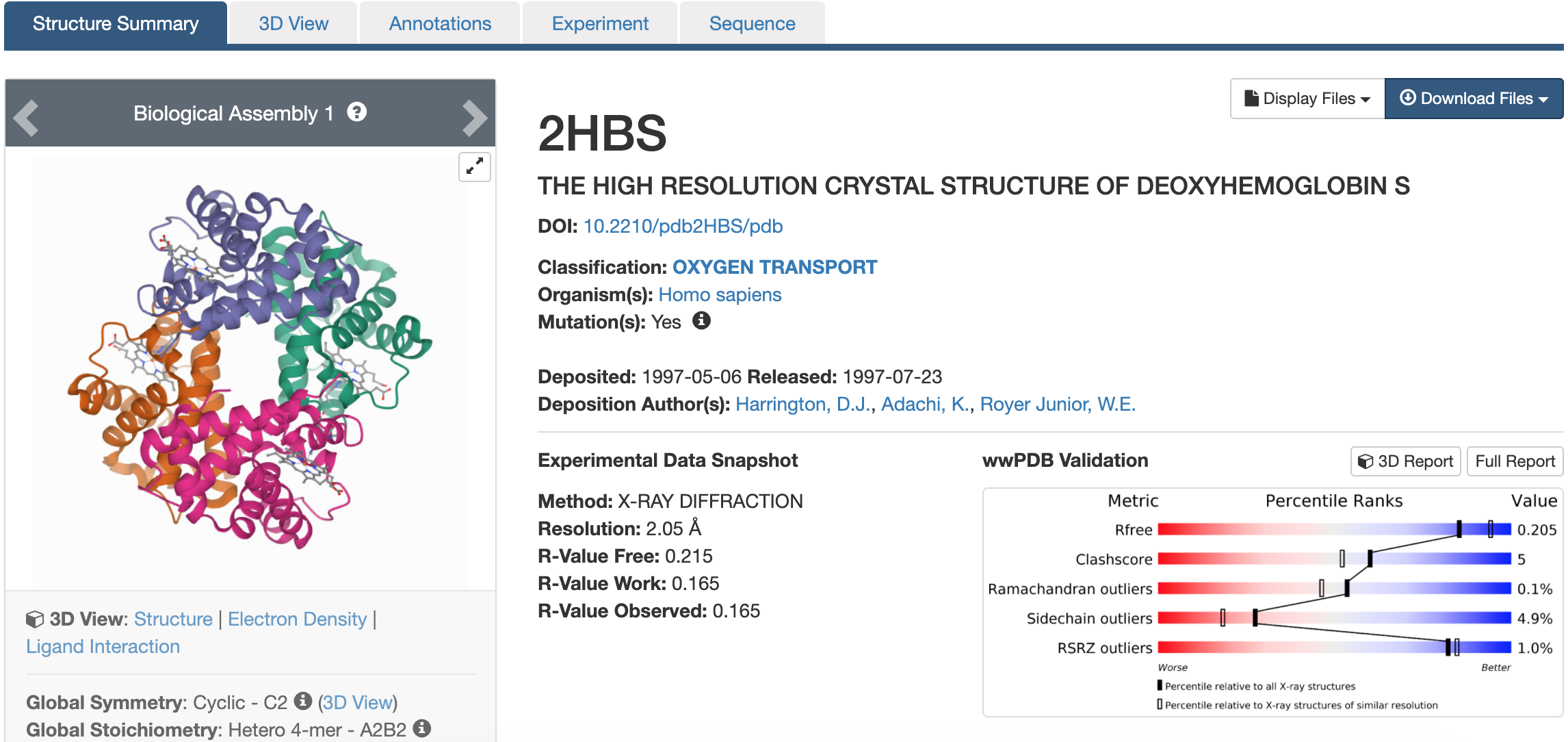
Figure 5.3: Katherine Cox (2021). Screenshot of the cystic fibrosis transmembrane conductance regulator page from Protein Data Bank https://www.rcsb.org/structure/2hbs. License: CC BY 4.0
Here you can view the structure and see information about how it was obtained, including what experimental methods were used and some statistics about how accurate we think the structure is, as well a link to the journal article for the structure.
If you click on the 3D View tab you will see an interactive model that you can rotate, zoom in, and select specific amino acids. You can also download the structure, though you will need a program that knows how to interpret it in order to make much use of it.
6.1.6 Summary
- Biological databases make vast amounts of scientific research freely available to anyone.
- Different databases can hold many different types of data including genome sequences, gene functions and roles in diseases, gene expression, and protein structure.
- Biological databases can be a bit overwhelming to explore. Focus on finding the information you’re interested in, and don’t be afraid to ask for help if you get stuck.